About a couple of months back, the host of the Chai Time Data Science show podcast Sanyam Bhutani had posted on twitter about releasing a dataset of the show on Kaggle. I was excited on knowing this. Primarily because I had just begun seriously watching podcasts around that time and secondarily because I felt I could use the data provided to understand which of the episodes could help me.
I headed over to the dataset hosted by Kaggle Competitions Grandmaster Rohan Rao at this repository. The data looked good and I put it down on my TODO list. I also happened to have a peek into the Discussions thread in the contest and came across this thread where Sanyam had announced the CTDS.Show Contest. It was scheduled to start on 21st June, 2020 and was supposed to go on till 14th July, 2020.
I put this down on my journal and life went on.
The Competition Goes Live
On the 21st of July, 2020 the contest went live and I was really excited to dive right into it. I had spent far too much time on Kaggle staying on the edge of the ring, being a mere spectator. I had finished my undergraduate studies and time was no longer a scarcity. I decided to dive in.
The data provided included the following:
- Cleaned Subtitles : Transcripts for each episode (.csv)
- Raw Subtitles : Transcripts for each episode (.txt)
- Anchor Thumbnail Types.csv
- Description.csv
- Episodes.csv
- Results.csv
- YouTube Thumbnail Types.csv
There was data for 85 episodes on the podcast. The Episodes.csv file was what I was targeting to analyse in specific and it had 36 features.
Along with the data, there were a few starter kernels provided by Parul Pandey and John Miller. These kernels were very fundamental to my submission. While Ms. Pandey’s kernel provided me the opportunity to understand storytelling and also the plotly library, Mr. Miller’s kernel provided the most important tips with which I had organized my submission.
My First Steps
The first task I performed was examining the data at hand. As suggested by Martin Henze on an episode of CTDS, the first step is to get a feel of the data at hand. Have an overview, look at the rows, columns etc.
After that, I decided to choose a principal research question that I wanted to answer via my analysis. My main goal was not really about winning the contest. It was more or less providing the host of CTDS with insights that would be actionable and useful to him. Hence, I decided to focus on a particular aspect rather than look at all the data at once.
I have always watched the CTDS episodes on YouTube and have always noticed how the number of people who watch it on YouTube are not “very high”. So, my principal research question(PRQ) was
How to increase the viewership of CTDS and reach a wider audience
With the PRQ in place, the next step was to learn more about the domain I had selected, YouTube. I didn’t know much about how it worked and also lacked a grip on the metrics described in the dataset. This article by HubSpot helped with those shortcomings and in a couple of hours, I was more or less good to go with the remainder of my work.
Creating the Story Flow
The PRQ was abstract. It didn’t provide specific detail on how to achieve what I was looking to achieve. Hence, the next step was to create a strong narrative or story flow that could help me understand what I had to focus on in my analysis. This could also help in organizing my thoughts and results while stitching together a story that could be both convincing and true to the contest organizers.
So, I decided to create my own storyboard, throw in some colour and try to see if there was a path I could build to explain my narrative and arrive at the answer to my PRQ. The picture beneath is the original story flow that I generated for my submission. Everything I did as a part of my submission was based on this.
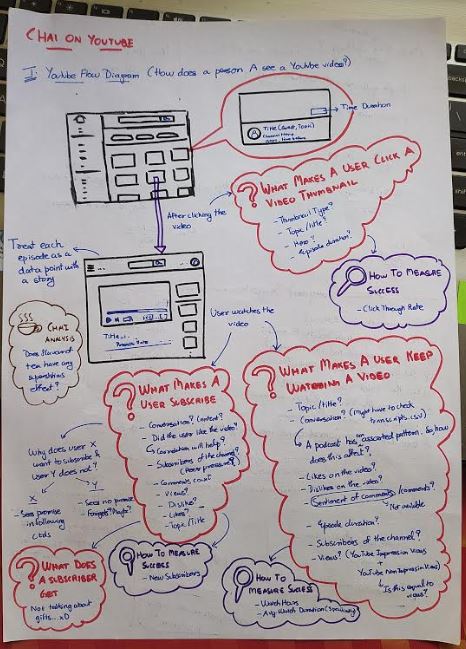
My apologies for the not-so-great quality picture.
Releasing The First Public Version
I released my first public version around 1.5 weeks into the contest. Within a couple of days, I saw the following tweet on Twitter by Sanyam.
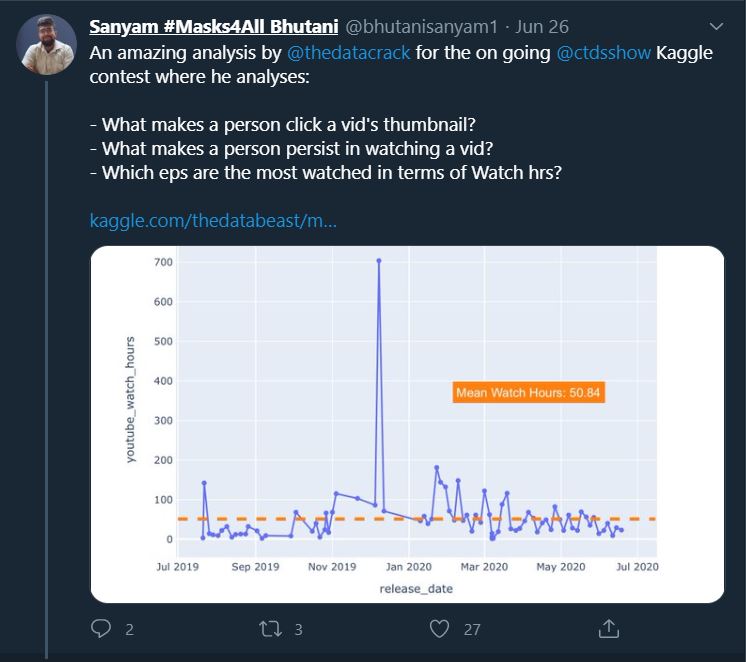
This was probably one of the most important points in the contest for me. Sanyam had tweeted out my submission’s preliminary version. This was important as it meant he did find my work valuable. And to my mind, that meant I had already succeeded with my initial goal - About submitting something valuable. It was now time to enhance my work and add new points of thought into it.
From here onwards, it was more analysis and more storytelling. And I kept refining my kernel over another 20 versions. Version 21 was my final submission.
Fears
I feel its important for me to write about it here, just to have a record of what I had overcome to make a valuable submission.
- I was not sure if I would complete my submission
- I was afraid that my submission might not be useful for CTDS
- I was sceptical about somebody copying my work if I made my kernel public too soon
The last fear is borderline paranoia. But I am sure it is a shared fear among all those who wish to display their work to the community. I got over it a little earlier than I would have expected. And I am glad I could.
Winning the Contest
On Monday (20th July, 2020), I got a message from Sanyam on Twitter about how I was the male winner for the CTDS contest. It was great to know! It was a great experience to be interviewed by Sanyam on the CTDS.Show in the wake of this win. My fellow winner Ms. Vrinda Prabhu provided some great insights through here compelling storytelling narrative and the entire interview was a very valuable learning process for me.
If you are interested, you could check out my winning submission here : Making perfect “Chai” and other tales :)”
Our interview : Anniversary Episode: Celebrating 1 Year of CTDS.Show ; CTDS.Show Kaggle Contest Results
The Final Leaderboard : CTDS.Show: Milestones
What could I have done better?
On the hindsight, I feel I could have worked a little more on Natural Language Processing to get more answers from the transcript data. Will probably have a look into that once I know some NLP on my own.
Thanks for reading!